在当今数据驱动的时代,企业对数据处理服务的需求日益严苛——既需要处理海量、多源、实时的数据,又要求系统能够实现自动化的高效管理,并提供全年无休的稳定服务。StarRocks,作为一款新一代的极速全场景MPP数据库,凭借其独特的架构设计与技术创新,正成为满足这一系列需求的卓越解决方案。其核心能力主要体现在以下几个方面:
一、 存算分离与弹性伸缩的架构基石
StarRocks采用先进的存算分离架构(尤其在云原生部署中),将数据存储与计算资源解耦。这种设计带来了两大核心优势:
- 弹性扩缩容:计算节点(BE)可以独立、快速地进行水平扩展或收缩,无需搬迁底层数据。当查询负载激增时,系统可自动或手动添加计算资源以提升并发处理能力;在闲时则可释放资源以降低成本。这种弹性是保障服务持续稳定、应对流量波动的关键。
- 高可用与持久化:数据在对象存储(如S3)或分布式文件系统中持久化,并通常配置多副本机制。即使部分计算节点发生故障,数据也不会丢失,并且系统能自动将任务调度到其他健康节点,实现故障的自动恢复,为7×24小时服务打下坚实基础。
二、 智能化、自动化的运维与管理
StarRocks内置了多项自动化管理功能,极大地降低了运维复杂度:
- 自动数据分布与再平衡:在数据导入时,系统会根据节点负载和数据进行智能分布。当集群扩容或缩容后,会自动触发数据的再平衡操作,使数据均匀分布,避免热点,保持查询性能最优。
- 智能物化视图:用户可以通过创建异步物化视图(Materialized View)来预计算复杂查询的结果。StarRocks的查询优化器能够自动、透明地选择最优的物化视图进行查询重写,无需修改应用SQL,即可实现查询速度的飞跃,这个过程完全自动化。
- 自动故障检测与恢复:系统持续监控各节点状态。一旦检测到节点异常,会将其自动隔离,并将该节点上的数据副本服务迁移至其他节点,查询和导入任务也会自动重新调度,保证业务连续性。
三、 极速统一的查询引擎保障实时服务
7×24小时服务意味着需要随时应对即席查询和实时分析。StarRocks的查询引擎为此提供了强大支撑:
1. 向量化执行引擎:全面采用向量化计算技术,充分利用现代CPU的SIMD指令集,将数据处理从传统的“一次一行”提升到“一次一批”,极大地提高了CPU利用率和查询吞吐量。
2. CBO优化器:基于成本的优化器(CBO)拥有丰富的统计信息,能够为复杂查询生成最优的执行计划,确保无论是大表关联、高并发点查还是复杂的Ad-hoc分析,都能获得稳定且极速的响应。
3. 联邦查询能力:通过External Table等功能,StarRocks可以直接查询外部数据源(如Hive、Iceberg、Hudi、MySQL等)的数据,无需繁琐的ETL过程即可实现数据的统一分析,简化了数据架构,降低了维护成本。
四、 高可靠与高可用的工程实现
- 多副本机制:数据在存储层默认采用多副本(通常为3副本)存储于不同节点或可用区,提供数据层面的高可靠,能够容忍节点甚至机柜级别的故障。
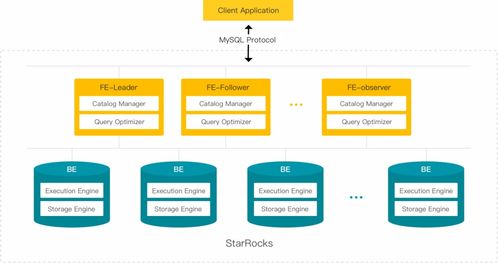
- 无单点故障的元数据管理:StarRocks使用基于Raft协议的高可用元数据服务(FE Follower),确保元数据的一致性与高可用。主FE故障时, follower能自动选举出新主,实现秒级切换,前端连接几乎无感知。
- 无缝的在线升级:支持滚动升级,可以在不影响业务正常运行(不中断查询和导入)的情况下,完成集群版本的迭代更新,满足了服务不间断的要求。
五、 完善的生态与监控体系
为了支撑自动化运维,StarRocks提供了丰富的API、与主流大数据生态(如Flink、Kafka、dbt等)的深度集成,以及详细的监控指标(可通过Prometheus+Grafana展示)。这使得运维人员可以构建自动化的监控告警、资源调度和性能分析平台,实现从“手动干预”到“智能自治”的转变。
而言,StarRocks通过其弹性可扩展的存算分离架构、高度智能化的自动化管理特性、极速统一的查询分析能力以及坚实的高可用设计,共同构建了一个能够应对大数据挑战、实现运维自动化和提供7×24小时稳定可靠数据处理服务的强大平台。它不仅降低了企业的总体拥有成本(TCO),更通过持续在线的数据服务能力,为实时决策和业务创新提供了关键动力。